Note 4 Extended ER Features
Lecturer: Jane YOU Note Author: Zhen Tong
After we have the basic knowledge of Entity-Relationship Model, this week, let’s go deeper into ER design tips.
First of all let’s take this example, and see why we need the first thing we are caring about Specialization.
Specialization
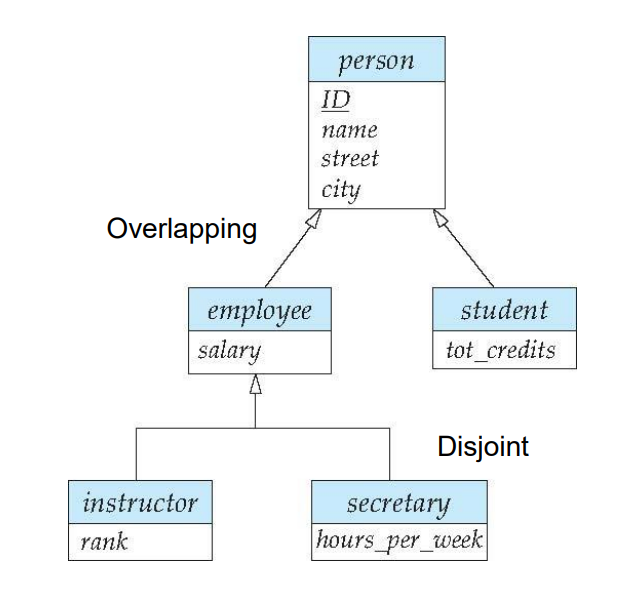
Overlapping Specialization: In an overlapping specialization scenario, entities can belong to multiple specialized sub-groups simultaneously. Consider an entity set "Person" and two sub-groupings "Employee" and "Student." In this case, a person can be both an employee and a student at the same time, which is why it's considered overlapping specialization.
Person (Higher-level entity set):
Attributes: Name, Date of Birth, Address, Phone Number
Employee (Lower-level entity set):
Attributes: Employee ID, Job Title, Salary
Relationships: Works_For (relating to a department)
Student (Lower-level entity set):
Attributes: Student ID, Major, GPA
Relationships: Enrolled_In (relating to courses)
In this example, a person can be a student and an employee at the same time, as some individuals work part-time while pursuing their studies.
Disjoint Specialization:
Let’s assume in this problem the secretary can’t be an instructor(which is a common case because they only study management🥱). In a disjoint specialization scenario, entities can belong to only one specialized sub-group. Consider an entity set "Employee" and two sub-groupings "Instructor" and "Secretary." In this case, a person can be either an instructor or a secretary, but not both, which is why it's considered a disjoint specialization.
Employee (Higher-level entity set):
Attributes: Employee ID, Job Title, Salary
Relationships: Works_For (relating to a department)
Instructor (Lower-level entity set):
Attributes: Employee ID, Subject Taught, Office Location
Relationships: Teaches (relating to courses)
Secretary (Lower-level entity set):
Attributes: Employee ID, Department, Extension Number
Relationships: Assists (relating to an executive or manager)
Okay, now let’s take over this problem. How do we do?
A very intuitive way is you create a separate database schema for each class (or entity) in the specialization hierarchy. This is the specialization via schemas also known as the "Schema per Class Hierarchy" approach. Here's how it works and its drawbacks:
1. Form a Schema for the Higher-Level Entity:
Create a database schema for the higher-level entity in the specialization hierarchy. This schema includes attributes that are common to all entities in the hierarchy. The primary key for the higher-level entity is typically included in this schema.
schema attributes person ID, name, address student ID, GPA employee ID, salary
2. Form a Schema for Each Lower-Level Entity Set:
For each lower-level entity in the specialization hierarchy, you create a separate schema. These schemas include the primary key of the higher-level entity and local attributes that are specific to each lower-level entity.
Drawback: The main drawback of this approach is that it can lead to complex queries and potential performance issues when retrieving information about a specific entity. Here's why:
When you want to access information about a lower-level entity (e.g., an employee), you need to perform joins between the high-level schema (e.g., "Person") and the low-level schema (e.g., "Employee"). This means you must access two relations and perform JOIN operations to retrieve the complete information about an employee.
Join operations can be computationally expensive and may result in slower query performance, especially when dealing with large datasets.
Additionally, managing and maintaining multiple schemas can be more complex and require extra effort.
However, this approach offers the advantage of maintaining data integrity and ensuring that each entity type has its own specific attributes. It's suitable when there are substantial differences between entities in terms of attributes.
Another way is to represent specialization as schemas is known as the "Single Table Inheritance" approach. In this approach, you create a single database schema for each entity in the specialization hierarchy. Each schema includes all the local attributes for that entity and any inherited attributes.
1. Form a Schema for Each Entity Set:
For each entity in the specialization hierarchy, you create a separate schema or table.
Each schema includes not only the local attributes specific to that entity but also any attributes inherited from higher-level entities.
| schema | attributes |
|---|---|
| person | ID, name, address |
| student | ID, name, address, GPA |
| employee | ID, name, address, salary |
Drawback: The primary drawback of this approach is data redundancy.
Since each schema includes all local and inherited attributes, some attributes may be stored redundantly for entities that belong to multiple lower-level entities. For example, if a person is both a student and an employee, their name, street address, and city might be stored redundantly in both the "Student" and "Employee" schemas.
Despite the data redundancy drawback, this approach has the advantage of simplifying queries. You don't need to perform joins to retrieve data specific to a particular entity type, as all the data is available in a single table.
Completeness Constraint
Next, think of a bigger question, is a person necessary to be either a student or an employee? The answer depends on the problem context but in reality, someone like a visiting scholar can not fit into these two categories. This is the Completeness Constaint problem.
It specifies whether an entity in the higher-level entity set must belong to at least one of the lower-level entity sets within a generalization. There are two types of completeness constraints: total and partial.
Total Completeness Constraint:
In a total completeness constraint, it is specified that every entity in the higher-level entity set must belong to one of the lower-level entity sets. In other words, there are no entities that exist solely at the higher level; they are always specialized into one of the lower-level entities.
Example: If we have a generalization hierarchy that combines "Person," "Student," and "Employee," with a total completeness constraint, every person must be either a student or an employee, ensuring that no person exists without one of these specific roles.
Partial Completeness Constraint:
In a partial completeness constraint, it is specified that an entity in the higher-level entity set may or may not belong to one of the lower-level entity sets. In this case, there can be entities at the higher level that are not specialized into any of the lower-level entities.
Consider an entity-relationship model that represents vehicles, with a generalization hierarchy involving "Vehicles," "Cars," and "Trucks."
Total Completeness Constraint:
Total completeness would mean that every entity in the "Vehicles" higher-level entity set must belong to one of the lower-level entity sets, "Cars" or "Trucks." No vehicle can exist without being classified as either a car or a truck.


Partial Completeness Constraint:
Partial completeness allows for the possibility of entities in the higher-level "Vehicles" entity set that are not specialized into "Cars" or "Trucks." Some vehicles, like a bus, can remain unclassified in this case.

Aggregation
Recall that aggregation is often used when you have a complex entity that can be broken down into smaller, related entities. In this case, you're discussing the ternary relationship proj_guide, which involves students, instructors, and projects, and you want to model evaluations of students by instructors on projects using an entity called "evaluation."
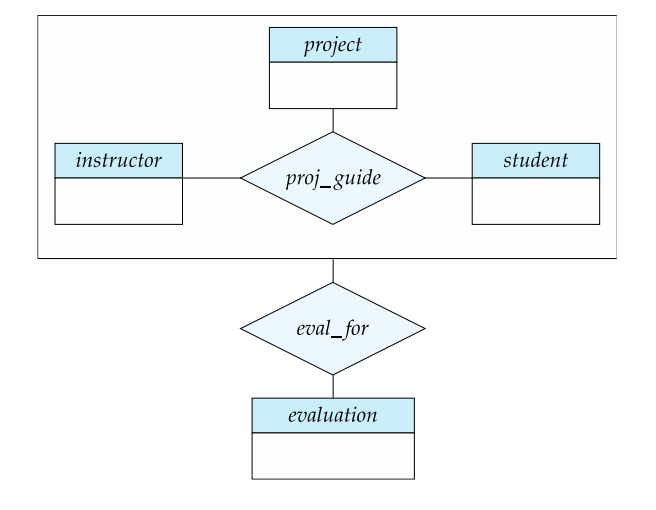
******************Reduce to Relational Schemas******************
Now how can we take this aggregation into Relational Schemas?
The way we do this is encode the aggregation directly into a schema, because it has the nature of a table.
eval_forSchema:This schema will capture the aggregation of data related to evaluations. It includes attributes from the "evaluation" entity and links them to the primary keys of the associated entity sets.
s_IDis the primary key from the "student" entity.project_idis the primary key from the "project" entity.i_IDis the primary key from the "instructor" entity.evaluation_idis the primary key of the "evaluation" entity.
Here's what the "eval_for" schema might look like in SQL-like notation:
CREATE TABLE eval_for ( s_ID INT, -- Student ID project_id INT, -- Project ID i_ID INT, -- Instructor ID evaluation_id INT, -- Evaluation ID -- Other attributes specific to the evaluation entity -- ... (evaluation_date, evaluation_score, etc.) PRIMARY KEY (s_ID, project_id, i_ID, evaluation_id), FOREIGN KEY (s_ID) REFERENCES student (student_id), FOREIGN KEY (project_id) REFERENCES project (project_id), FOREIGN KEY (i_ID) REFERENCES instructor (instructor_id), FOREIGN KEY (evaluation_id) REFERENCES evaluation (evaluation_id));Entities vs Attributes
Let's evaluate the two designs in the scenario of dealing with instructor information and phone numbers
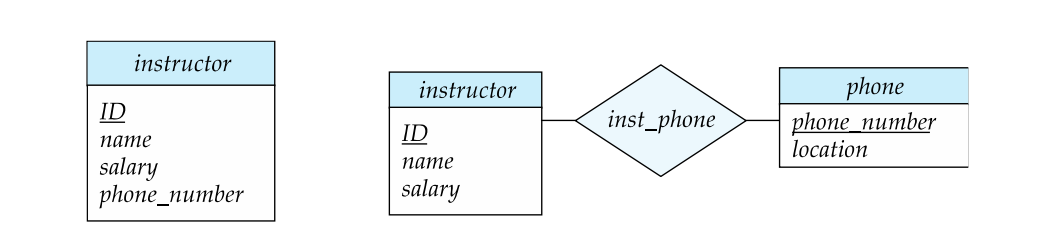
Attributes Design: Instructor as an entity with attributes:
xxxxxxxxxxCREATE TABLE instructor ( ID INT PRIMARY KEY, name VARCHAR(255), salary DECIMAL(10, 2), phone_number VARCHAR(15) -- Assuming phone numbers as strings);Entities Design: Instructor and phone as separate entities with a relationship:
x-- Create the 'instructor' tableCREATE TABLE instructor ( ID INT PRIMARY KEY, name VARCHAR(255), salary DECIMAL(10, 2));
-- Create the 'phone' tableCREATE TABLE phone ( phone_number VARCHAR(15) PRIMARY KEY, location VARCHAR(255) );
-- Create the 'instructor_phone' join table to establish the relationshipCREATE TABLE instructor_phone ( instructor_ID INT, phone_number VARCHAR(15), PRIMARY KEY (instructor_ID, phone_number), FOREIGN KEY (instructor_ID) REFERENCES instructor(ID), FOREIGN KEY (phone_number) REFERENCES phone(phone_number));Here's a comparison of the two designs:
Attributes Design:
Simplicity: The attributes design is simpler and more straightforward, as it represents the instructor's phone number as an attribute of the instructor entity.
Entities Design:
Additional Phone Information: It allows you to capture additional information about phone numbers (e.g., location) if that information is relevant.
Entities vs Relationship Sets
In database modeling, the choice between using entity sets and relationship sets depends on how you want to represent the data and the nature of the associations between entities.
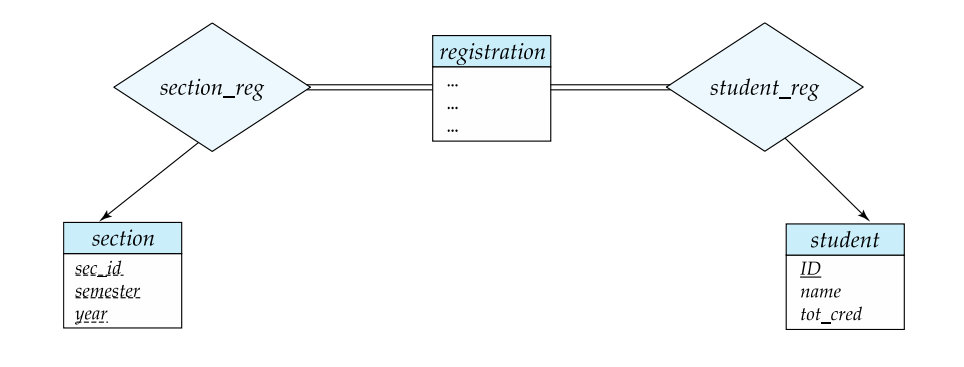
Here's an analysis of the example you provided, which involves the "section," "registration," and "student" entities:
Entity Sets Approach:
In this approach, you represent both students and sections as entities, and you use a relationship to associate them:
xxxxxxxxxx-- Entity SetsCREATE TABLE student ( student_id INT PRIMARY KEY, name VARCHAR(255), -- Other student attributes);
CREATE TABLE section ( sec_id INT PRIMARY KEY, semester VARCHAR(255), year INT, -- Other section attributes);
-- RelationshipCREATE TABLE registration ( student_id INT, sec_id INT, -- Other attributes like registration date, grade, etc. FOREIGN KEY (student_id) REFERENCES student(student_id), FOREIGN KEY (sec_id) REFERENCES section(sec_id));In this design:
Each student and each section are represented as entities with their attributes.
The "registration" table captures the relationship between students and sections. It includes foreign keys referencing the primary keys of the "student" and "section" tables.
Relationship Sets Approach:
In this approach, you represent the "registration" as an entity itself to describe the relationship:
x
-- Entity SetsCREATE TABLE student ( student_id INT PRIMARY KEY, name VARCHAR(255), -- Other student attributes);
CREATE TABLE section ( sec_id INT PRIMARY KEY, semester VARCHAR(255), year INT, -- Other section attributes);
-- Relationship Set (Registration)CREATE TABLE registration ( registration_id INT PRIMARY KEY, student_id INT, sec_id INT, -- Other attributes like registration date, grade, etc. FOREIGN KEY (student_id) REFERENCES student(student_id), FOREIGN KEY (sec_id) REFERENCES section(sec_id));In this design:
Each student and each section are represented as entities with their attributes, just as in the entity sets approach.
However, the relationship between students and sections is captured using a "registration" entity with a unique identifier ("registration_id"). The relationship attributes are part of this entity.
Which Approach to Choose:
Consider your specific modeling requirements and whether you want to capture additional information about the registration process when deciding between these two approaches.
Non-Binary to Binary
No offense 🌈 but converting non-binary relationships to binary form is a common practice in database design when you want to represent relationships involving more than two entities using binary relationships. This approach simplifies data modeling and maintains the integrity and clarity of the relationships. Here's how it's done:
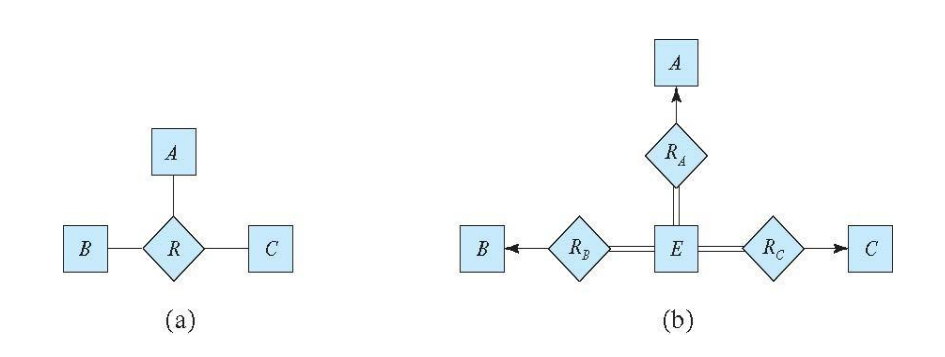
Create a Middle Artificial Entity Set:
To represent the non-binary relationship, you introduce an artificial entity set (let's call it "E"). This artificial entity set will serve as a connector between the original entities involved in the non-binary relationship.
Create Binary Relationship Sets:
For each original entity set involved in the non-binary relationship (let's call them A, B, and C), create a binary relationship set between "E" and the respective entity set. This effectively converts the non-binary relationship into several binary relationships.
Assign Entities to Binary Relationships:
For each tuple (a, b, c) in the non-binary relationship (let's call it "R"), you create a new entity (let's call it "e") in the artificial entity set "E." Then, you establish relationships between "e" and each of the original entities (a, b, and c) using the binary relationship sets created in step 2.